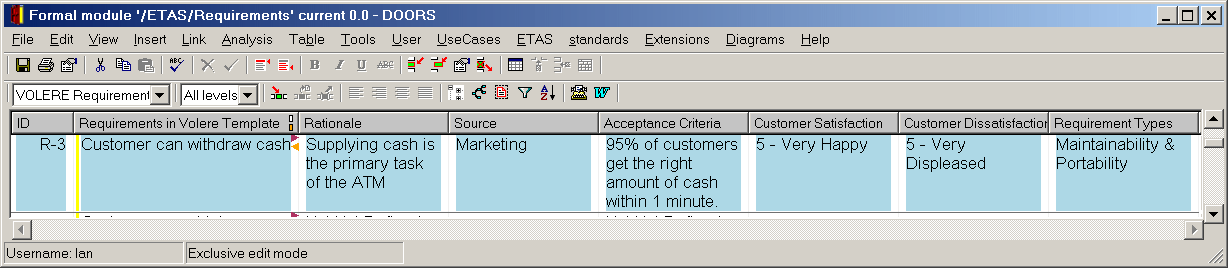
Figure 1:Volere Template implemented in Doors
Traceability is tedious to construct "by hand" but Requirements Management (RM) tools only provide engineers with the bare minimum of support for the central task of creating links.
This paper describes the experience of designing a custom toolkit, for use with an RM tool, to allow engineers to specify several types of traces from product requirements able to exist in multiple versions, back to existing use cases or to other requirements, for automatic linking.
While successful, the approach raises difficult questions about how to cope with more complex patterns of traceability, such as system/subsystem hierarchies and product families.
The basic industrial fact about traceability is that Requirements Management (RM) tools provide support for essentially manual construction of traces – each link is typically constructed by a requirements engineer, who personally selects the source and target of a link and creates it by an operation such as drag-and-drop, e.g. [DOORS 2003], or by clicking on a cell of a link matrix, e.g. [Requisite Pro 2003]. This is always a substantial effort. When several different types of link, e.g. 'satisfies', 'depends on', and 'conflicts with' need to be created together, as was the case in the project described here, it is awkward and inconvenient. What the project wanted was a way of creating and visualizing relationships suitable for everyone to use.
The existence and role of RM tools has already been mentioned. All the commercial RM tools take slightly different approaches, but the amount of support that they provide for traceability is de facto what requirements engineers consider the starting point for making traces "by hand".
An earlier workshop paper [Alexander 2002] describes the Scenario Plus use case toolkit's basic use case and traceability features, and the Doors requirements database environment in which the toolkit operates. It also summarizes related work by other authors so that summary is not repeated here.
The underlying platform for this project was Doors, a requirements tool which provides document-like modules containing objects that can be linked individually, and a programming language, DXL which gives access to the tool’s data structures [Doors 2003]. The Scenario Plus toolkit is a family of DXL scripts that support Use Case and other models [Scenario Plus 2003].
An ETAS Inc. project wanted to develop a product's requirements using the VOLERE template [Volere 2003], to manage them in the Doors requirements tool [Doors 2003], and to trace them both to related requirements (with dependencies and conflicts) and to related use cases. It wanted non-Doors users to be able to review the requirements.
The project experimented with the Scenario Plus toolkit [Scenario Plus 2003] and found it convenient for handling traceability among the use cases, and for its ability to export a use case model to HTML for non-Doors users to browse, but lacking support for similar traceability from requirements to use cases.
Accordingly, the project specified in broad terms the development of tools to construct a Volere template in Doors, a mechanism for the semi-automatic construction of requirements traceability links, and an extended exporter to permit Web-style navigation of requirements and use cases together.
Figure 1:Volere Template implemented in Doors
Setting up the Volere template in Doors was no problem. It was represented as a tabular view with text- and list-valued attributes (Figure 1), all created automatically. However, the project wanted to be able to handle requirements for different versions of its product. This meant setting up a reconfigurable list of versions with a tool to add new versions, and then exporting the requirements to different documents (possibly overlapping) according to which version(s) each requirement was in, and to link those requirements to the use cases.
The goal was clearly to make this look easy so that project members would not think it anything out of the ordinary. The result would be a many-to-many mapping because several versions of several requirements might be linked to a use case, or more likely to an individual use case step.
The Scenario Plus approach for use cases relies on (fuzzily) matching use case names referenced in the text of use case steps with the names of existing use cases [Alexander 2002]. But it is not usual to name use cases directly in requirement text, nor indeed to name dependee or conflicting requirements in the text either.
To provide a more natural way for people to document desired traceability links, a view 'Relationships to Link' was set up by a new initialisation tool, with text attributes in columns to hold the names or identifiers of use cases and requirements that the project wanted to link its requirements to [Figure 2].
The new analysis tool then simply scans the three columns – for 'satisfies' links to use cases, 'conflicts with' links to conflicting requirements, and 'depends on' links to dependee requirements, and creates links "by attribute" as specified by the project team. Since users might specify non-existent targets, a report window displays any errors.
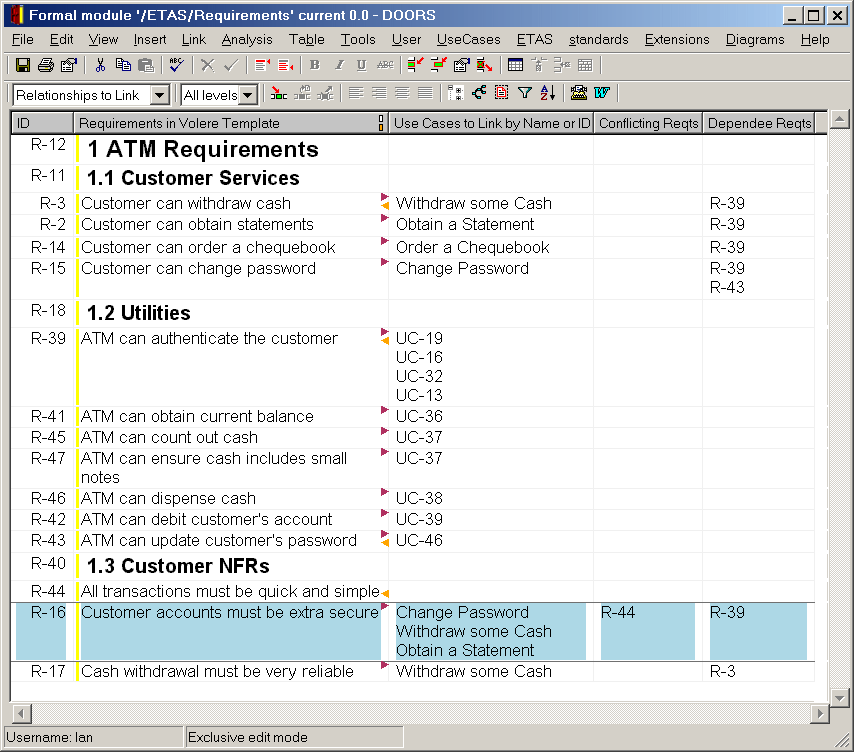
Figure 2: Requirements marked up with named or identified targets of 3 kinds of desired links
The highlighted object (R-16) illustrates the scope for many-to-many relationship
It can be seen from Figure 2 that the task of specifying links is very straightforward: you just type in the use case names or object identifiers of whatever you want to link to, in the appropriate column – since all three types of link are represented in the same view, no switching is necessary.
The job of the exporter is in principle equally simple. Since HTML hyperlinks are unidirectional whereas Doors links can be followed in either direction (though the links have a single logical direction) every Doors link is exported to a hyperlink from the Doors source to the Doors target, and a second hyperlink from the Doors target to the source.
However, the export task is complicated by the need to create a different HTML page for each version of the requirements (Figure 3). A Doors link from a requirement marked as existing in two product versions, say v1 and v2, to a use case step has to be exported as a link from the v1 requirements page to the use case, and a link from the v2 requirements page to the same use case.
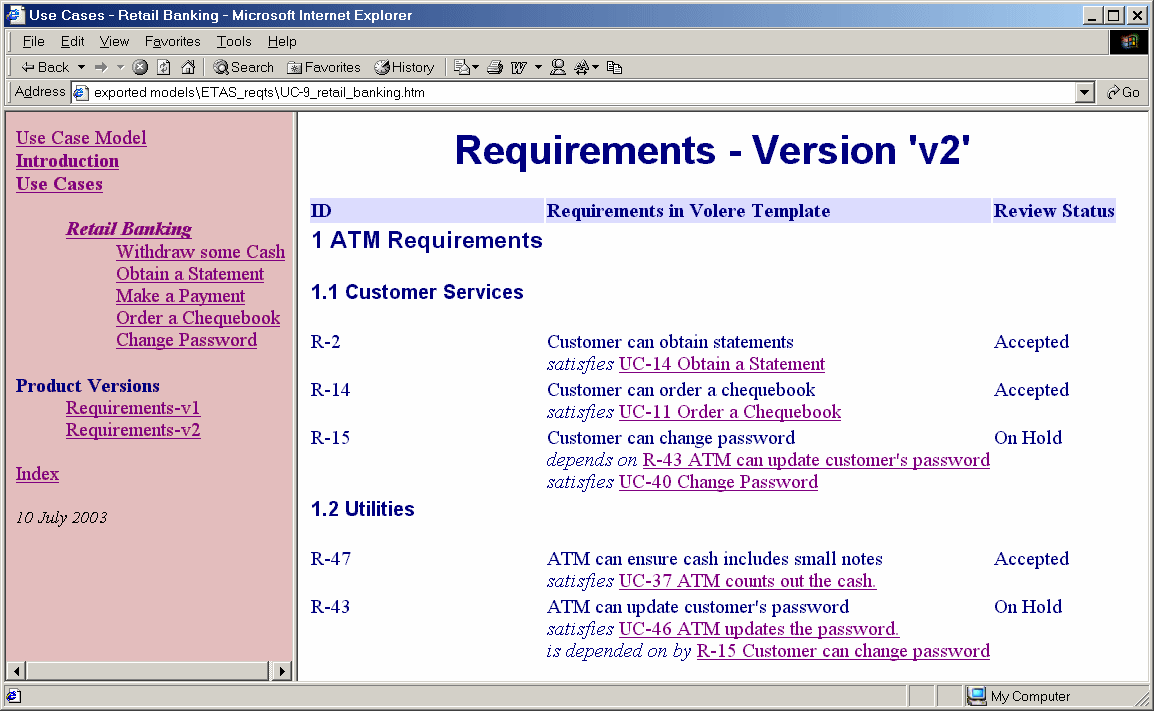
Figure 3: Requirements Version pages added and traced to the Exported Use Case Mode
Figure 3 also illustrates the result of exporting a 'depends on' link: both forward and reverse hyperlinks, the latter labelled 'is depended on by', are listed under the relevant requirements. Reverse names for the various types of traceability link are stored in a lookup table used by the exporter.A typically simple but awkward problem is what to do when there are many links from a use case to different versions of the requirements. If each link is displayed as a piece of text, the basic story is submerged in a mass of link text – you can't see the wood for the trees.
One solution is to give users the option of labelling hyperlinks with the full name of the target (as illustrated in Figure 3), or with only an identifier (as illustrated in Figure 5). This option is provided by a radio box control in the exporter window (Figure 4), making the display of traceability highly visible to the user. An alternative would be to maintain configuration switches in a module attribute of the use case model and/or the requirements.
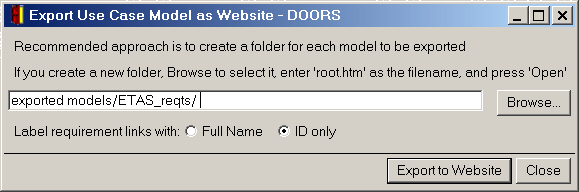
Figure 4: Exporter allowing the user to choose how to display traceability link
The multiplicity of requirements versions is visible as a list of version pages in the Table of Contents (frame on the left of Figures 4, 5).
The requirements themselves, however, can readily be filtered for export to produce a page containing an exact definition of the work to be done in each product version, with no sign of duplication (Figure 3).
The export also has to provide reverse links from use case steps to all the versions of the associated requirements, so multiple links per use case step are possible (Figure 5).
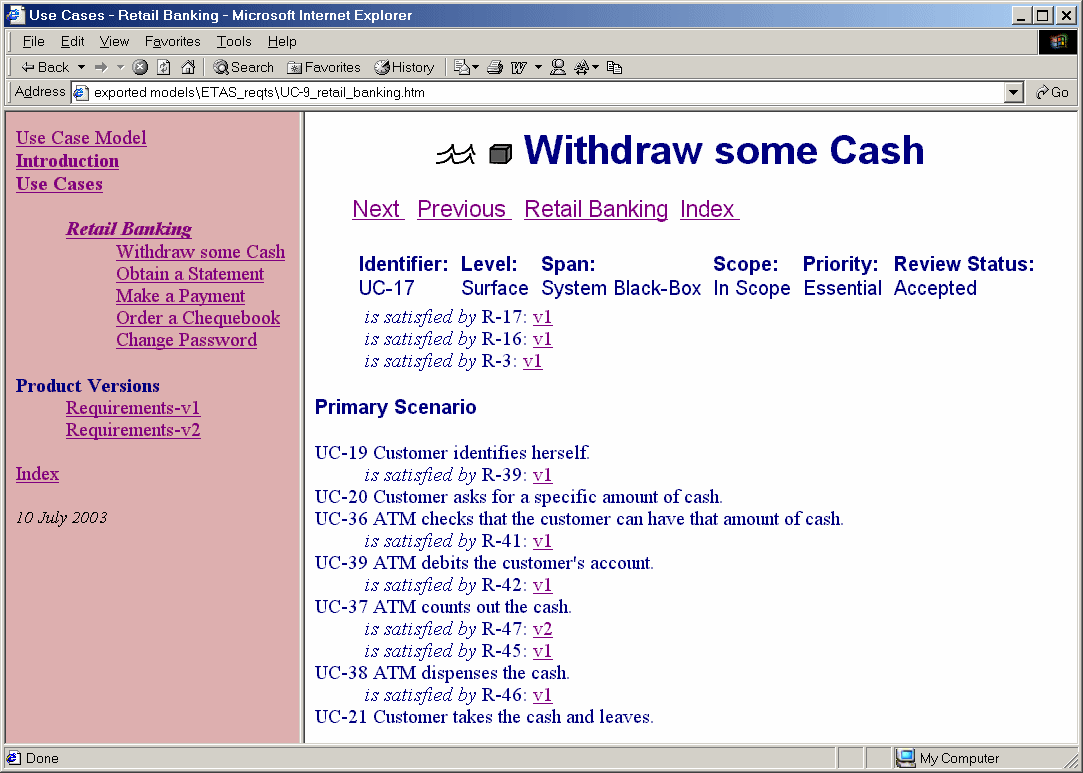
Figure 5: Use Case Exported Complete with Traceability Links from Requirements by Version
The new toolkit makes it straightforward to create VOLERE-style requirements in the DOORS environment, and to create a complete pattern of traceability links without any 'manual' linking operations. The output is both a fully-navigable hypertext and a properly- structured project in the DOORS database.
Throughout the project, we aimed to provide users with an intuitive interface to the tools and to the data – before and after export. It is hard to measure the success of this but as the toolkit is in service it seems to have met a real need and overcome one limitation of the previous toolkit.
The approach has several obvious limitations, and some that are perhaps not so obvious.
Exporting a fixed-format display to HTML is simple and efficient, but if a user finds that the amount of detail in e.g. the hyperlinks is insufficient, there is no remedy apart from exporting the whole model with a different setting.
A more dynamic approach would be to publish alternative views to a web server. DoorsNet makes this a simple process, provided that the views correspond to Doors database views (which the exported HTML model does not – it provides an elegant tree of web pages where Doors has a single module), and provided that the users have access to and are willing to use DoorsNet, a much less common tool than a web browser.
Another possibility would be to export a family of web pages with hyperlink 'buttons' to switch between expanded and condensed views. That would double the exported page count and increase complexity: and the exporter is already the most complex tool in the toolkit.
The approach was intentionally simple, for reasons of time, budget, and usability. That choice has led to a practical toolkit that should be able to cope with any reasonable number of use cases, linked to some thousands of requirements organized into any reasonable number of succcessive versions.
It is not, however, immediately applicable to more complex patterns of traceability in larger projects, such as system/subsystem hierarchies or product families.
Where requirements are organized into many documents (Doors modules), and these are in turn organized into a hierarchy of folders or "projects", tasks like locating the right use case or requirements modules could become quite challenging. It might be necessary to construct an index of relevant modules to avoid having to search the entire database, for instance. In addition, the current exporter assumes just one requirements module, and it does not attempt to export further (e.g. subsystem) modules that might be linked to that in its turn.
Another assumption in the approach that certainly needs to be challenged is that versions form a series. In a product line, it is commonplace for versions to grow not only as a series with time, but sideways into product variants, as when a car becomes available in saloon, cabriolet, and estate variants [Weber 2003]. These typically share many features and requirements (i.e. the same requirements often occur in several product variants), though some requirements occur only in one variant.
The simple multi-valued "Product Version" attribute approach does to some extent permit the definition of variants – engineers can just mark up the requirements that belong to multiple variants and the exporter will create separate product variant pages. What it does not do is to permit the requirements themselves to vary (other than by being copied and specialised by editing), or for different variants to have different statuses.
Product line requirement engineering is still in its infancy, and among the unresolved questions are how to recycle requirements effectively from one product (and project) to another [Heumesser 2003]. One promising approach is to use higher-level descriptions, that abstract away from the requirements themselves, as indexes to the requirements.
Two kinds of description that might serve this purpose are use cases and features. However, neither will be available to support reuse in a product line unless project engineers feel that the effort of creating traceability links between them and requirements is justified. They will be more likely to feel that it is, when links can be created easily and at least semi- automatically, and when they see that existing traceability links actually save them time and energy in finding requirements and identifying problems. The latter is a pump-priming or "bootstrapping" challenge; the former isanswerable by the creation of toolkits, such as the one described here, for different environments.
Requirements engineering contains several hard problems, most of which concern human issues such as how to encourage people to think out and document their requirements, and how to get engineers to construct traceability links.
The main challenge in creating tools to support such activities is to make them simple, inviting and yet powerful enough for people to want to use them. The approach taken here – a combination of specialised link-by-attribute and tailored export to HTML – is one way of encouraging people to actually practise requirements engineering.
The support of Mr Don Nutter of ETAS Inc. for the work described here is gratefully acknowledged.
Alexander 2002: Alexander, Ian, Towards Automatic Traceability in Industrial Practice, Proceedings of the First International Workshop on Traceability, Edinburgh, 28th September 2002, pp 26-31
Doors 2003: website of Telelogic, http://www.telelogic.com
Heumesser 2003: Heumesser, Nadine and Houdek, Frank. Towards Systematic Recycling of System Requirements. In Proceedings of the 25th International Conference on Software Engineering, Portland, May 2003, pp. 512-519.
Requisite Pro 2003: website of IBM Rational, http://www.rational.com
Scenario Plus 2003: website (free requirements toolkits & templates), http://www.scenarioplus.org.uk
Volere 2003: website (free requirement templates), http://www.volere.co.uk
Weber 2003: Weber, Matthias and Weisbrod, Joachim, Requirements Engineering in Automotive Development: Experiences and Challenges. IEEE Software, Jan./Feb. 2003, Vol. 20, No. 1, pp. 16-24.
More Papers, Consultancy and Training on
Ian Alexander's Home Page